…double check that your browser zoom is set to 100%.
#things-that-took-longer-for-me-to-realize-than-im-willing-to-admit #what-is-happening #is-the-internet-broken
…double check that your browser zoom is set to 100%.
#things-that-took-longer-for-me-to-realize-than-im-willing-to-admit #what-is-happening #is-the-internet-broken
You’ve probably felt bad about writing something like this before:
1 2 3 4 5 | |
Queries in the controller are a pain to write, but more importantly, they are a pain to read, and a pain to maintain. Any future developer (including future you) will have to parse some raw SQL to understand which @posts are going to be rendered. And bizarrely, changes to Post or Author could force changes in PostsController—if you change Author#active to Author#active_at, or change Post to has_many :authors, or add a Post#published_at date… well, you get the idea.
So how do we write scopes that are easy to read, and resilient to changes? By keeping a strict rule: conditions live in scopes on their respective models. Don’t let the internals of you models leak all over your application!
This is what the controller looks like when you apply this rule:
1 2 3 4 5 | |
Now the scopes say what they do in plain language, and if any of the scope internals change, you won’t have to update PostsController.
Let’s see what happens when we try to write the with_active_authors scope on the Post model:
1 2 3 4 5 | |
Now we have a condition for the authors table in the Post class. This is a problem for all the same reasons writing conditions in the PostsController was a problem. We can solve it by moving the authors condition to the Author class, and using merge to apply it in with_active_authors:
1 2 3 4 5 6 7 8 9 10 11 | |
Now every condition lives on the correct model.
Many people would ask at this point: why bother? Isn’t it easier to write the condition when you need it? Maybe you could extract a scope when you start reusing the same condition a second or a third time?
The problem is that it’s easy not to notice when you are rewriting the same condition for the nth time. You have to remember to grep the project.
I also find that when a set of conditions is rewritten every time they are used, bugs occur. Something like this always happens: you remembered to order by published_at, but you forgot the fall-back order is created_at because not all records have a published_at date. Or any of the thousands of similar quirks that accumulate when several programmers add code on top of an imperfect data set. This is avoided if you define one canonical scope on the model itself.
Your ActiveRecord models are meant to encapsulate all the logic for querying their respective tables. That is their entire point. Use them! Don’t be afraid to aggressively move logic into the correct class, and don’t forget to use merge when you want to apply scopes in other classes.
So you are building a search form. It produces a hash of query params, all of which are optional. How do you build up the query in ActiveRecord? Do you nil-check every param?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | |
Ick. This should feel bad to you. Every param repeats the pattern of [check if param is present], if so [apply param to query]. That adds tons of visual noise. We can make it way more expressive.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | |
That’s the entire solution. Read on if you want to learn more about it.
Let’s compare the application of one parameter in the search method:
From…
1 2 3 | |
To…
1
| |
That’s massively more expressive! We cut out all the cruft of nil-checking, and query-building. We’re left with a single, expressive method call. But the cruft hasn’t disappeared. We’ve moved it:
1 2 3 4 5 | |
The query-building noise (query = query.where()) is gone completely.
We are still left with nil-checking (if date.present?; end).
How is that any better?
Well, now it is encapsulated in its own method that is only 3 lines, and thus can be understood at a glance.
The method can be reused without re-writing the nil-checking logic.
But wait. You may have noticed something odd about the signed_up_after scope.
If date is nil, then if date.present? will return nil, and the lambda will return nil.
If we try to chain other calls on after it, then it will blow up!
1 2 | |
But ActiveRecord takes care of this for us. If the scope lambda returns nil, then it will return the scoped object, so other scope calls can be chained after. It’s equivalent to this class method:
1 2 3 4 5 | |
If you use the scope method, then that’s one less then you have to repeat for every query method.
Because it forces us to use the correct number of params.
1 2 3 4 5 | |
Proc params are optional:
1 2 3 4 5 | |
If I call with_name, and forget to pass a param, there’s 99% chance that’s a mistake.
I’d like hear about that in the form of an exception!
Atom is already good enough to become my primary editor. Its combination of ease of extensibility and powerful editing could make it the editor of choice for serious programmers. The fact that it’s open source and already has a strong community means it has a very low chance of abandonment and stagnation.
What the core team needs to do now is improve the (already quite good) responsiveness to remove all doubt about the viability of JS/HTML technology stack, and ship binaries for Windows and Linux. And in fact, those are the goals that the core team has identified for the 1.0 release. I believe that they can do it, and then there will be nothing preventing Atom from being your #1 editor for the next 10+ years.
Don’t take my word for it, though. Let’s see how far along Atom is already. I made a list of features I thought I needed to use an editor in my day-to-day work:
A few nice-to-haves:
This Atom has built in with the atom command. Just like Sublime Text, you will always want to launch Atom from the command line by cd-ing into your project directory and using atom . so Atom will use that as your project directory.
This is how I navigate files without the mouse: incremental search to jump to a nearby match, then emacs-style character and word jumps to refine the selection as necessary. The problem is: theres no incremental search available! I’ll have to try to get by without it.
These are available by default. That’s a relief because in most OS X apps alt-b and alt-f are bound to insert special characters (∫ƒ).
cmd-shift-f brings this up, and it is awesome because the results list it keyboard navigable. Also, the filter field filters by paths (app/) or by file patterns (.rb). It seems really fast too. Then! If you enter something in the replace field, the replacements will live preview in the find results. Atom’s search and replace is already the nicest out of any that I’ve used.
The cmd-t file opener that was created first in TextMate has become the gold standard for file navigation. That functionality was copied in Sublime, ported to emacs and vim, and now copied to Atom. It works well. As a bonus, cmd-b does the same thing, but only for the buffers (tabs ;) that are open. cmd-shift-b searches only the files have been modified since last commit (the git status list).
Ctags is the default recommendation for symbol indexing, but it has to be installed and maintained by the user. You are going to want a package to maintain ctags, append and delete them when you save a file. There doesn’t seem to be a package for this at the momement. It also doesn’t support Coffeescript or CSS.
Goto takes a promising approach to this problem. By using the Atom syntaxes to find symbols, it (theoretically) supports all the languages that Atom does. It also updates the symbol index for you, so there is no manual ctag maintenance. The problem is that it is an early stage of development, and needs optimizing and debugging.
Neither option is perfect. Goto seems like it will be the best solution, but right now it is too slow. I think I’ll be manually managing ctags for my projects until Goto gets to a point where it can be used.
With either system you use, (cmd-r) is for jumping to a method definition within a file, (cmd-shift-r) is for jumping to methods across a project, and to jump from a method call to its definition, place cursor over method call, and press cmd-opt-down.
This is available via the ruby-test package. In your shell: apm install ruby-test, then re-open your project so the package can load. I had to change the package settings by opening preferences (cmd-,) searching for Ruby Test in the installed packages (left sidebar), and then configuring it to use Zeus.

1 2 3 4 5 6 7 8 | |
^ That is just about the easiest integration I’ve done with a test-running package and my project’s test setup, and it works perfectly. <3
Something that I had when I used emacs, and have missed since, is project-wide autocomplete. That is, not just autocompleting with words from the same file, but something that autocompletes on method definitions across the whole project you are working on. Ideally, it would know what is a method call in this syntax across the whole project and make those completions available, while preferring matches from the current file.
Nothing exists like that right now. There is the built-in autocomplete function, that will autocomplete when you press ctrl-space. That will only autocomplete matches in the current file. Then there is the autcomplete-plus package, which will match across all open buffers, which is marginally better. By default, it pops up the autocomplete menu every time you start typing. There is an option to disable auto-activation, and change the keyboard shortcut to ctrl-space, from the default ctrl-shift-space. I’m going to try it out for a bit, but I’m not sure how useful it will be.
Cursor duplication is now an essential part of how I work. It’s cognitively lighter-weight than a find-and-replace, but it allows you to do quick batch updates. Atom has decent support, with both cmd-d and ctrl-shift-down. The details that I miss from Sublime are the ability to skip a match with cmd-k and to undo a match with cmd-u.
Both are supported by the Whitespace package that ships with Atom.
This is one of the nicest features of Atom, even in its beta stage. Not only is the in-app interface for managing packages pretty stellar, there is also a command line utility, apm. That allows you to search for, install, and uninstall packages. The one big shortcoming I found was not being able to easily search for packages, either by their popularity or by their purpose. apm could use a more complete rubygems.org-type site, and probably a rubytoolbox.org type categorizer as well.
Atom (unsurprisingly, from Github) ships with amazing git integration: color bars in the gutter to indicate changes, branch name in the lower right and a lines changed summary. Git plus adds some vim-fugitive-like functionality, including adding, commiting, pushing, pulling and branching.

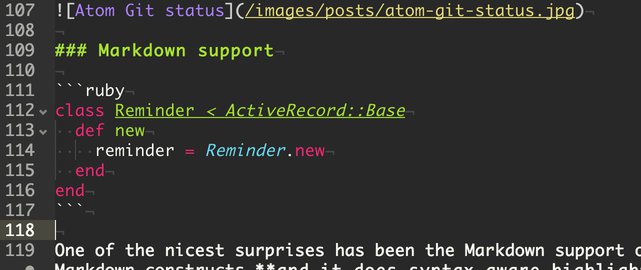
One of the nicest surprises has been the Markdown support of the Atom Monokai theme. It does highlighting/styling on most Markdown constructs and syntax-aware highlighting inside code fences!! The snippets that come with the Markdown package are also handy, and I find myself using them to add links, images and bold styling as I write this. One other note: the Whitespace package is configured to allow trailing whitespace for markdown files. One more thing that just works that would have taken some fiddling in Sublime or other editors.
I stumbled upon an icon that looks a little more modern than the official icon. Download the full-size version here.
![]()
Atom already exceeds my expectations. My main concern was the speed and responsiveness, because in earlier versions that was bad enough to make it unusable. Not so anymore. In fact, in the current version, lag is rarely an issue. And the capabilities of the editor and related packages are already impressive. The lack of incremental search was the biggest dissapointment, but that was balanced by best-ever implementations of search-and-replace and test integration. I’m confident enough now in the editor, its chosen technologies, and its community to make the switch to using Atom as my main editor. To the next 10 years of programming with Atom!
Two of my favorite commands in Sublime Text are upper_case and lower_case. I’ve remapped <Caps Lock> to <Ctrl>, so if I have to type SOME_LONG_CONSTANT_IN_SCREAMING_SNAKE_CASE, I can type it all out in lower case and press super+k, super+u.
Now I’d like the same thing for title case. I’d like to highlight some text, and type super+k, super+t and have it all titleized.
I don’t know if Sublime has this function, so I open up the help menu and search 'title case'. A command is available under Edit > Convert Case > Title Case.
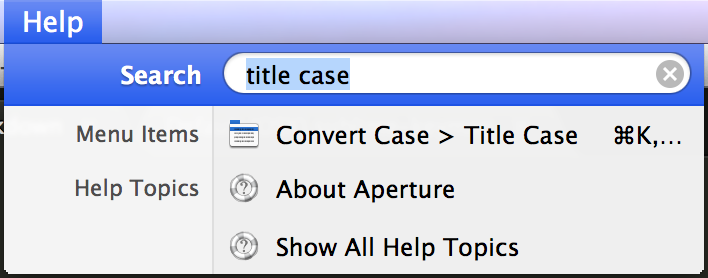
To find the internal command name for that function, open up the console (ctrl+`) and type this to tell Sublime to log every command it receives:
1
| |
Now select Title Case in the Edit menu, and it will show up in the Sublime console.

Now we know that the command name is title_case (who knew?), we can create a keyboard shortcut for it. Open up the menu Sublime Text > Preferences > Key Bindings — User and add an entry:
1
| |
This key combo is a little different. If you pass an array to the "keys" key like that, it means to release the keys between presses. So you hold super, press and release k, then press and release t. It’s common in Sublime to prefix keyboard shortcuts with super+k for commands that are higher level or less commonly used.
If you want to use the more common pattern of pressing all keys at once, you can see many examples in Sublime Text > Preferences > Key Bindings — Default. Here is one example:
1
| |
I immediately added a second shortcut for toggling word wrap:
1
| |
If you need to pass arguments to a command, that’s how it’s done.
We know how to add shortcuts—let’s make it as easy as possible to add new ones. Open the console again, make sure Sublime is logging commands, then open the Key Bindings — User file. This is what is logged:
1
| |
open_file is the command, and the the rest are the args. Put that into a shortcut:
1
| |
Now when I press super-k, s, the user shortcuts file opens. You can pick a shortcut that makes sense to you.
Sublime is cool because it’s easy to hook into the editor to customize it. Use your new power to automate your workflow. Any time you feel the pain of doing something with the mouse, consider creating a keyboard shortcut.
In the last post, I layed out what I think are the basic rules for dealing with time zones in a Rails app:
Those are the basics, but they don’t cover every situation. In particular, we could add a 4th principle:
Every time you exchange time information with an outside system, you must either 1) send time zone info to the external system, or 2) once you receive times back from the system, convert them into the correct zone, or 3) both. We’ll look at a common example of an external system in web applications: the database. In our case, it’s Postgres. We’ll have to use strategies 1 and 2.
The last post showed that Rails will convert times to the Time.zone when retrieving them from the database. What about writing them to the database? Take this example from the reminder app, again for the user in Hawaii:
1 2 3 4 5 6 7 8 9 10 11 | |
Notice that when the time is written to the database, it is stored in UTC, but when we reload the reminder and return remind_at, Rails converts to HST again. update_column also works:
1 2 3 4 5 | |
When possible, use ActiveRecord’s safe interpolation to build time queries. It will correctly handle the time zones for you.
Let’s try to retrieve that reminder that we just updated:
Safe interpolation works:
1 2 3 | |
We query for reminders before 12 noon on August 21. Our reminder is for 10:30am on that day, so it is returned, as we expect.
Remember that times are stored in UTC in the database, so Rails converts your time from HST to UTC when building the SQL query.
What happens if we try to interpolate with standard Ruby string interpolation?
1 2 3 | |
Standard interpolation does not convert the time to UTC, and Postgres doesn’t know to interpret it as HST. Postgres runs a query for reminders before 12 Noon UTC, which is 10 hours before 12 Noon HST, the time that we meant.
You should be using safe interpolation anyway. If for some reason you need to use regular string interpolation, you can tell Postgres to interpret the string as a time and zone with the Postgres type TIMESTAMP WITH TIME ZONE.
1 2 3 | |
Postgres correctly interprets '2014-08-21 12:00:00 -1000' as 12 Noon HST (or 10pm UTC), and returns the correct reminder.
What if we do time calculations inside the database? We have to pass the time to the database so that it makes the right calculation. DATE_TRUNC is an example that requires us to do this.
Say you want to do a calender view for your reminder app. You want to return a list of days, and a list of the names of the reminders for each day. You want a speedy query, so you will group by day in SQL using Postgres' DATE_TRUNC function. How will you group by days in the user’s time zone, rather than the database’s time zone?
The user in Hawaii has a reminder for 5pm HST, August 21st. You try to your DATE_TRUNC query for reminders that week, and this is what you get:
1 2 3 4 5 6 7 8 9 10 11 12 | |
The reminder is showing up for the 22nd, not the 21st. What happened? In Postgres, the time is stored in 2014-08-22 03:00:00 UTC. When DATE_TRUNC('Day') truncates the time values, what we get is ‘2014-08-22 00:00:00’. We need to convert the time to HST before we truncate the time values. For this purpose we can use Postgres' TIMESTAMPTZ AT TIME ZONE
1 2 3 4 5 6 7 8 9 10 | |
Now the reminder is showing up on the 21st, which is correct for our user in Hawaii. What’s going on?
Rails actually uses TIMESTAMP WITHOUT TIME ZONE columns in Postgres to store datetimes.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
Normally, this would not make sense, because a timestamp without a time zone does not make sense. '2014-05-29 12:00:00' (without time zone info) could be one of dozens of different times in all the time zones across the globe. There’s no way to know what time is meant without the time zone. Rails gets around this by storing everything in UTC. The database column doesn’t include time zone information, but the time zone is implicitly UTC.
Back to the example: in order to do our DATE_TRUNC calculation, we have to convert the time-zone-less (implicitly UTC) time values to the local time first. We can do this with the Postgres function TIMESTAMPTZ AT TIME ZONE. TIMESTAMPTZ is the Postgres type for a timestamp with a time zone included. TIMESTAMPTZ AT TIME ZONE requires that we tell it which time zone to use:
1 2 3 4 5 6 7 8 9 10 11 12 13 | |
Fortunately, you can pass the time zone as a Postgres INTERVAL, which can easily be created in from a string: '-10:00'::INTERVAL. Even more luckily, Rails offers Time.zone.now.formatted_offset to return the current user’s time zone in exactly that format.
1 2 | |
(Potential gotcha: using Time.zone.formatted_offset, without the now. That always returns the standard offset, even when it is Daylight Savings Time! My tests were off by 1 hour until I figured that one out.)
We interpolate the formatted_offset into the SQL query for the solution:
1 2 3 4 5 6 7 | |
Oops. Rails 4 casts values returned in custom SELECT clauses, but it doesn’t handle timezones in this case. We can get around this inconsistency by getting the raw value, and parsing it ourselves.
1 2 3 4 5 6 | |
We break out Time.zone.parse, and Ruby parses it correctly, as a Hawaii time. Does this work with our DATE_TRUNC example problem?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | |
Yup! We get the 21st in HST, which is exactly what we want. We would then call to_date and get Thu, 21 Aug 2014 to indicate that we mean the whole day, and not any specific time. We can now display reminders for the correct day.
That’s one example of working with time zones in Postgres. Hopefully it gives you a good idea of the problems that arise when using time zones in conjunction with an external system. We got to try both 1) passing time zone info to the external system so that it could do time zone calculations and 2) converting times into the correct zones after they were returned from the external system. The specifics were particular to Postgres, but the types of issues you deal with should be similar for any external system, be that a reporting sytem, queuing, email, whatever.
If you have any questions about Postgres and time zones, or external services and time zones, feel free to email me at the address in the footer.
People talk about handling time zones in Rails like it’s super scary and mysterious, but I don’t think you should be scared. Follow a few simple principles, and Rails makes things easy:
Time values without zone info are ambiguous—avoid them. 'Jan 12, 2014, 11:00 AM' could mean 11 AM in London or in 11 AM in Honolulu, and those events occur at very different times.
Fortunately, Rails allows us to add zones to our times with the setting Time.zone.
Set Time.zone to the user’s time zone in a controller before_filter, and Rails will automatically convert every time into that zone. The Time.zone will be set for the length of the request, and every time value retrieved from the database will automatically be converted to Time.zone.
Say we are building a reminder app that needs to work across all time zones. The user has already entered their local time zone, and we stored it on the column users.time_zone:
1 2 3 4 5 6 7 8 | |
Now, for the remainder of the request, all times will be represented in HST (Hawaii Standard Time):
1 2 3 4 5 | |
If you display to the reminder’s remind_at time, it will be displayed correctly, in the user’s time zone:
1 2 3 | |
The time will display to the user in their local zone:
1 2 | |
To get the current date and time in the local zone, use the special methods Date.current and Time.current, rather than Time.new and Date.today:
1 2 3 4 5 6 7 8 9 10 11 | |
Another potential trouble spot is calculating times. Suppose you want to show your user their reminders for “tomorrow”. If you define tomorrow as 12:00AM-11:59PM UTC, you are going to show the user in Hawaii the wrong information. Fortunately, once you set the time zone, Rails' convenience methods like beginning_of_day, end_of_month, etc. return the correct times:
1 2 3 4 5 6 7 | |
Say the user from Honolulu enters the time '1pm May 14th, 2014'. The time they are thinking of is 1pm May 14th, HST. How do we interpret this string correctly as 1pm Hawaii Time? We can use Time.zone.parse:
1 2 3 4 5 6 7 | |
If we have a number of integers from the user (like params from a set of select fields), representing the time, we can use Time.zone.local:
1 2 3 4 5 6 7 | |
I think these three principles are the basis for good time zone hygiene. If you keep them in mind, you should be alert to most time zone gotchas.
Next time we’ll face two of the most fearsome of beasts: time zones and Postgres! Until then.
I was able to do this with Parallels 8. There was some conflicting information on the forums, and no clear answer, so I thought I would write it up. It’s easy to do, but not obvious from the Parallels interface or help:
With the new versions of OS X, you need to find the disk image inside the installer you download from the App Store.
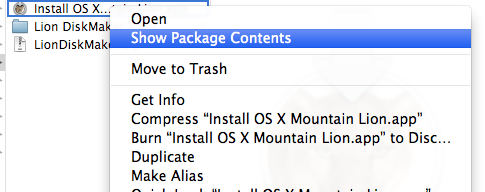
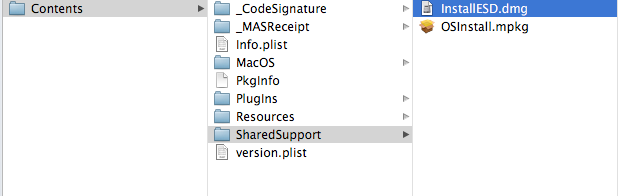
This is the OS X Installer disk image. Copy it to some place you can find it easily.
The normal OS X installation process boots up in a new window.

This one scared me a little—it looks like it is going to force to overwrite your current Macintosh HD. In fact, it is on a virtual disk, so you can install there with no problem.
After upgrading to Rails 3.1.4 and Ruby 1.9.3, running features produced dozens of instances of this warning:
activesupport-3.1.4/lib/active_support/core_ext/string/output_safety.rb:23: warning: regexp match /.../n against to UTF-8 string
That’s not very fun to look at, so I cracked open activerecord:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | |
You can see the offending line gsubbing out characters that should be escaped. Fortunately, there already is a commit for this issue, and it has been backported to the 3-1-stable branch, it just hasn’t been released yet. Until it is released, if we don’t want to look at those UTF-8 warnings, we can use the fix for a monkey patch (1.9 only, use the other half of the aforelinked commit if you are on 1.8):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
The commit that fixes this in activesupport should be released with the next version of Rails, so we can give ourselves reminder to remove this patch once we update:
1 2 3 4 5 | |
Props to this guy on StackOverflow for the spec reminder idea.